1.背景
上一次blog写着写着崩掉了,这次一定写完一节保存一节。 目前从事go语言的后台开发,在集群通信时需要用到thrift的rpc。由于集群间通信非常频繁且并发需求很高,所以只能采用连接池的形式。由于集群规模是有限的,每个节点都需要保存平行节点的连接,所以链接池的实现方式应该是map[host]chan conn。在go语言中,我们知道channel是线程安全的,但map却不是线程安全的。所以我们需要适当的加锁来保证其线程安全同时兼顾效率。
2. 链接池的一般设计
新建链接时,需要给定目标地址
获取链接时,需要给定目标地址,若链接池存在链接,则从链接池返回,若不存在链接,则新建链接返回
链接池中存放的链接总是空闲链接
连接使用完后需放回链接池
放回链接池需要给定目标地址
放回链接池时若链接池已满,则关闭该链接并将其交给gc
3.链接池的一般定义
1
2
3
4
5
6
7
8
9type factory func(host string) conn
type conn interface {
Close() error
}
type pool struct {
m map[string]chan conn
mu sync.RWMutex
fact factory
}以上是一个通用链接池的实现,用了channel和读写锁,暂时不考虑链接超时等问题。我们的目的是探索这个链接池在高并发情况下的线程安全和get,put效率问题。所以下来我们给出实验主程序。
4.测试主程序
测试主程序如下所示
pt是记录的get,put次数,采用原子操作进行累加,其耗时忽略不计。
hosts为集群规模,也是map的大小,一般来说不会太大。
threadnum为并发的协程数
为了方便,此处直接使用net.dial作为工厂方法实现
每一个协程是一个死循环,不断地进行get,put操作。每次操作会使pts加1。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43func main(){
var pts uint64
p := &pool{
m :make(map[string]chan conn),
mu:sync.RWMutex{},
fact:func(target string)conn{
c,_ :=net.Dial("","8080")
return c
},
}
//打印线程,打印get,put效率
be := time.Now()
go func (){
for true{
//此处先休眠一秒是为了避免第一次时差计算为0导致的除法错误
time.Sleep(1 *time.Second)
cost := time.Since(be) / time.Second
println(atomic.LoadUint64(&pts)/uint64(cost),"pt/s")
}
}()
time.Sleep(1*time.Second)
//打印线程完,此处等待一秒是为对应打印线程第一次休眠,尽量减少误差
//集群规模
hosts := []string{"192.168.0.1","192.168.0.2","192.168.0.3","192.168.0.4"}
//并发线程数量
threadnum := 1
for i:=0;i<threadnum;i++{
go func(){
for true{
target := hosts[rand.Int() % len(hosts)]
conn := p.Get(target)
//------------------使用连接开始
//time.Sleep(1*time.Nanosecond)
//------------------使用连接完毕
p.Put(target,conn)
atomic.AddUint64(&pts,1)
}
}()
}
time.Sleep(100 * time.Second)
}5.单协程情况下的效率
5.1 单协程get & put实现
单协程模式下,我们不必考虑线程安全的问题,也就不必加锁。此时的get,put实现如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23func (p *pool)Get(host string) (c conn){
if _,ok := p.m[host];!ok{
p.m[host] = make(chan conn,100)
}
select {
case c = <- p.m[host]:
{}
default:
c = p.New(host)
}
return
}
func (p *pool)Put(host string,c conn){
select {
case p.m[host] <- c:
{}
default:
c.Close()
}
}
func (p *pool)New(host string)conn{
return p.fact(host)
}5.2 测试结果
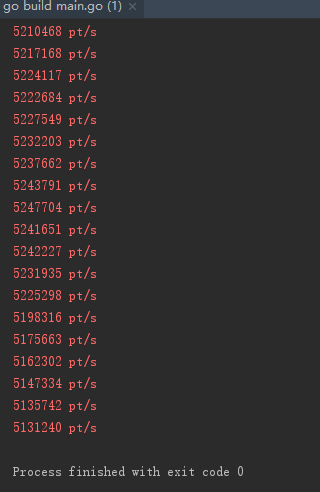
我们设置threadnum为1,测试结果如下。其速度大概在5,000,000 次/秒
6.并发情况下效率-全写锁
6.1 全写锁的get & put 实现
为了保证并发情况下的线程安全,我们需要使用读写锁,那么对get和put操作究竟该如何加锁呢,最安全的形式当然是全写锁的形式,单其效率肯定是最低的,因为这样同一时刻总是只有一个协程在进行写或者读。
1 | func (p *pool)Get1(host string) (c conn){ |
6.2 测试结果
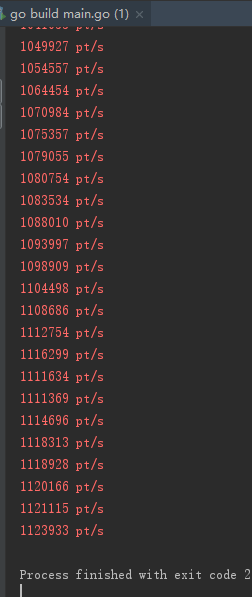
6.2.1 全写锁下 的多协程测试结果
我们设置threadnum为4,测试结果如下,其速度大概在1,000,000次/秒
6.2.2 全写锁下单协程测试结果
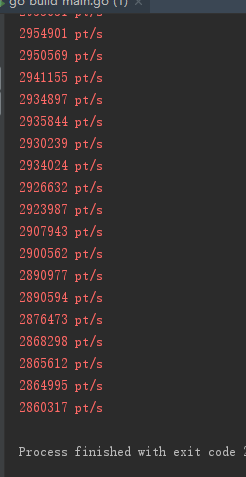
如果我们将threadnum设置为1,再次测试,其速度为2,800,00次/秒。可以看到,多协程会降低效率,因为协程间切换也会有时间消耗。但我们经常听说多协程会提高运行速度,这也是对的,那么什么时候多协程会提高运速度呢,这就是我说的链接使用时间的问题,当连接使用时间大于锁竞争和协程切换时间的时候,我们用多协程会提高效率。而实际使用中,连接的使用时间总是存在的且一般都大于锁竞争时间和协程切换时间。
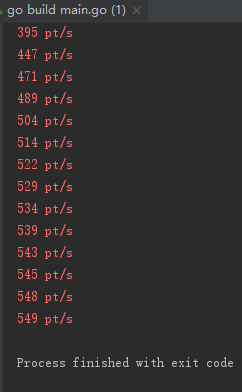
6.2.3 单协程下存在链接使用时间的的测试结果
在主程序中,我们在get和put间加上休眠时间,此处设置休眠时间为1毫秒即链接使用1毫秒后放链接池。同时协程数设置为1。单协程情况下,其速度大概如下500次/秒。可以看到实际的效率大幅度降低。
6.2.4 多协程下存在链接使用时间的测试结果
同样保持链接使用时间为1毫秒,协程数量设置为4,测试结果如下。其速度大概为2,000次/秒,刚好是单协程的4倍。所以实际情况下多协程的使用需要慎重考虑,并不是多协程一定能提高程序的处理速度,相反在某些情况下会降低程序的执行速度。由于本次测试的是链接池的性能和安全,接下来的测试不再添加链接使用时间,只单纯的测试读写锁和效率的问题。本小节算是一个附加测试。
7.并发情况下效率-读写锁1
由于全写锁没有实际的使用意义,所以我们需要使用读写锁来提高效率,那么如何保证线程安全添加读写锁呢。首先对于我们的map结构来说,当有写操作的时候,我们的读操作应该是不可靠的,所以不能进行,当读操作时,我们不希望有写操作但其他协程也能同时读取,这桥恰符合读写锁的作用原理。
当加写锁时,所有的读写均不可用
当加读锁时,所有的写操作不可用,读操作可用
7.1 读写锁1 get & put实现
考察我们的put程序,只有对map的读,所以只需要加读锁,而在get中,包含了两部分,第一次写操作和第二次的读操作,所以我们很简单的我们想到,需要使用两次锁,第一次写锁,第二次读锁。
1 | func (p *pool)Get2(host string) (c conn){ |
7.2 测试结果
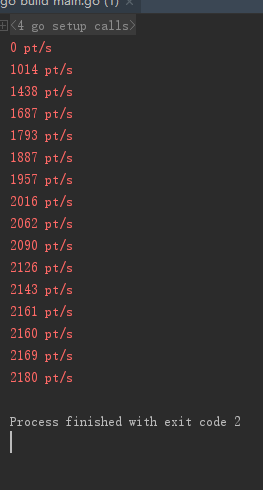
我们本来期望的是效率应该比全写锁要高一些,但实际情况是低一些,只有800,000次/秒。那问题出在哪里呢。从程序上来看,get多了一次加锁,所以导致锁竞争次数比全写锁要高一些,但我们并不能减少锁次数直接使用读锁,这样是不安全的,程序也会报错。所以我们给出另一种安全的读写锁形式。
8.并发情况下效率-读写锁
8.1 读写锁2 get & put实我们从实际的使用来看一下get程序,由于我们给定了hosts,所以其实对map的写入操作只会进行四次,但后来每次进行get时都会加一次写锁,这是没有必要的。仔细看一下第一次写锁,我们加的有些草率,因为首先会读取一次map来判断是否应该进行写入操作,所以我们可以通过增加一次读锁,来减少后来的加写锁。当然有人会说为什么不直接初始化map,这样就没有写操作,这我也考虑过,但是集群规模有可能会扩张并且会动态变化,直接初始化map会显得有些刻意,并且通用性也不强,与其他模块会产生耦合。所以这种做法并没有多少设计上的美感,相反会显得比较low。我们给出第二种读写锁如下。
1 | func (p *pool)Get3(host string) (c conn){ |
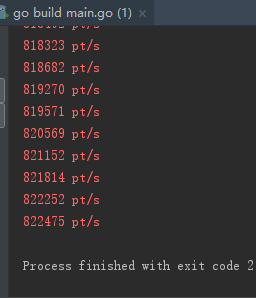
8.2 测试结测试结果如下,其速度大概在3,400,000次/秒。是全写锁性能的4倍左右。
9.defer对锁的性能影响
我们经常听说defer的执行效率低,其实是因为defer在函数返回时才执行,这对普通的函数并没有影响,但对所来说,如果我们可以提前释放锁,那么肯定能减少很多锁的无效占用。顺便我们测试一下defer函数对锁的性能影响,对8.1的get & put实现,我们将其中的defer全部替换为函数结束之前手动释放锁。其实只在put中有defer
9.1 无defer的 get & put实现
1 | func (p *pool)Get4(host string) (c conn){ |
9.2 测试结果
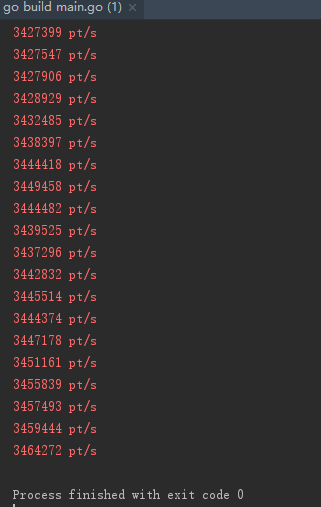
测试结果如下,仅仅修改了一处defer,速度达到接近4,000,000次/秒,性能提高了15%。还是非常可观的。
10.总结
这篇bolg真不容易,写了我好久
多协程提高程序执行速度是有前提的,并不能无脑提高程序速度
- map是非线程安全的,需要谨慎使用
- 读写锁性能比单纯的写锁(互斥锁)要高很多,尽量使用读写锁
- 读写锁的使用可以针对具体情况进行优化,还可以使用go race detector来检测是否安全
- 锁尽量手动释放,当然defer是一种非常优雅的写法,对效率要求不高的程序中我还是喜欢用defer