1.6.11 order by排序
asc:升序【默认】
desc:降序
1 | mysql> select * from stu order by ch desc; # 语文成绩降序排列 |
多列排序
1 | #年龄升序,成绩降序 |
思考如下代码表示什么含义
1 | select * from stu order by stuage desc,ch desc; #年龄降序,语文降序 |
1.6.12 group by 【分组查询】
将查询的结果分组,分组查询目的在于统计数据。
1 | # 按性别分组,显示每组的平均年龄 |
1 | 脚下留心: |
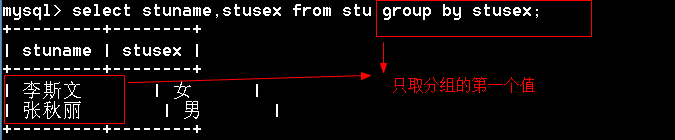
通过group_concat()函数将同一组的值连接起来显示
1 | mysql> select group_concat(stuname),stusex from stu group by stusex; |
1 | 多学一招:【了解】 |
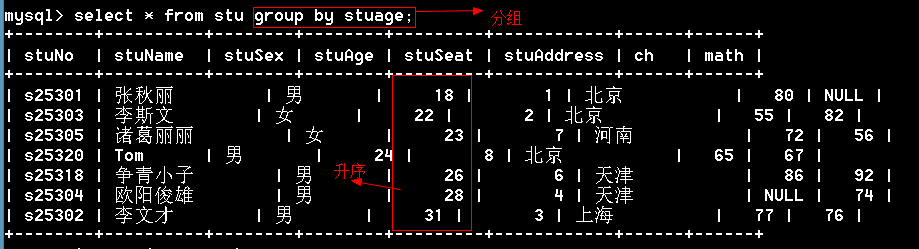
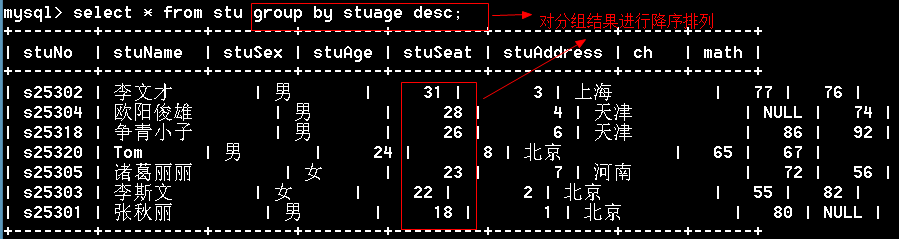
多列分组
1 | mysql> select stuaddress,stusex,avg(stuage) from stu group by stuaddress,stusex; |
1.6.13 having条件
1 | 思考:数据库中的表是一个二维表,返回的结果是一张二维表,既然能在数据库的二维表中进行查询,能否在结果集的二维表上继续进行查询? |
例题
1 | mysql> select * from stu where stusex='男'; # 从数据库中查找 |
思考如下语句是否正确
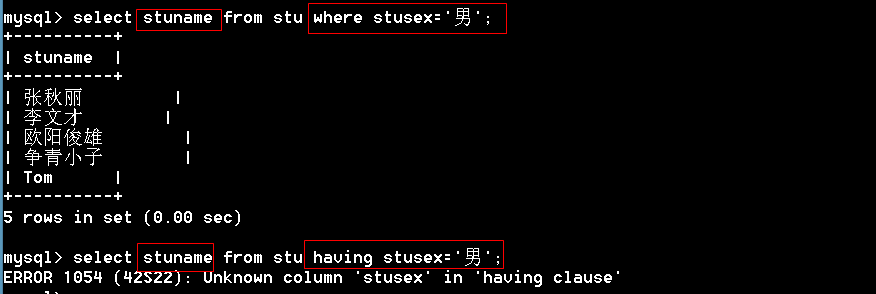

having和where的区别:
where是对原始数据进行筛选,having是对记录集进行筛选。
1.6.14 limit
语法:limit 起始位置,显示长度
1 | mysql> select * from stu limit 0,2; # 从0的位置开始,取两条数据 |
起始位置可以省略,默认是从0开始
1 | mysql> select * from stu limit 2; |
例题:找出班级总分前三名
1 | mysql> select *,(ch+math) total from stu order by total desc limit 0,3; |
多学一招:limit在update和delete语句中也是可以使用的。
1.6.15 查询语句中的选项
查询语句中的选项有两个:
1、 all:显示所有数据 【默认】
2、 distinct:去除结果集中重复的数据
1 | mysql> select distinct stuaddress from stu; |
1.7 union(联合)
插入测试数据
1 | mysql> create table GO1( |
1.7.1 union的使用
作用:将多个select语句结果集纵向联合起来
1 | 语法:select 语句 union [选项] select 语句 union [选项] select 语句 |
1 | mysql> select stuno,stuname from stu union select id,name from Go1; |
例题:查询上海的男生和北京的女生
1 | mysql> select stuname,stuaddress,stusex from stu where (stuaddress='上海' and stusex='男') or (stuaddress='北京' and stusex='女'); |
1.7.2 union的选项
union的选项有两个
1、 all:显示所有数据
2、 distinct:去除重复的数据【默认】
1 | mysql> select name from go1 union select stuname from stu; |
默认是去重复的
1 | mysql> select name from go1 union all select stuname from stu; # all不去重复记录 |
1.7.3 union的注意事项
1、 union两边的select语句的字段个数必须一致
2、 union两边的select语句的字段名可以不一致,最终按第一个select语句的字段名。
3、 union两边的select语句中的数据类型可以不一致。